
一、什么是字典树
Trie(字典树)指的是:某个字符串集合构造的有根树,是一种用于实现字符串快速检索的多叉树结构。Trie的每个节点都拥有若干个字符指针,若是插入或检索字符串时扫描到一个字符c,就沿着当前结点的c字符指针,走向该指针指向的结点。由于Trie字典树较好的利用了字符串的公共前缀,因此有效的节约存储空间。
Trie树典型应用是:用于统计,排序和保存大量的字符串(但不仅限于字符串),所以经常被搜索引擎系统用于文本词频统计。它的优点是:利用字符串的公共前缀来减少查询时间,最大限度地减少无谓的字符串比较,查询效率比哈希树高。
它有3个基本性质:
A、 根结点不包含字符,除根结点外每一个结点都只包含一个字符;
B、 从根结点到某一结点,路径上经过的字符连接起来,为该结点对应的字符串;
C、 每个结点的所有子结点包含的字符都不相同。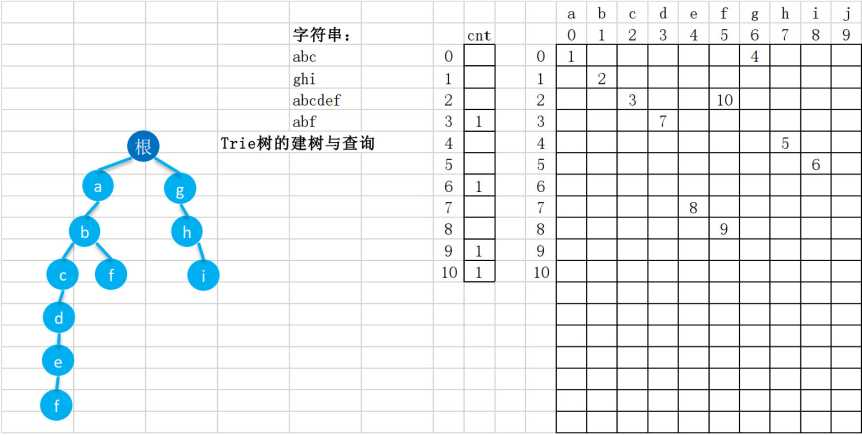 邻接矩阵a[i][j]表示第i层字符j的下一个字符的编号,cnt[i]用来标记以i号结点结束的单词的个数。
邻接矩阵a[i][j]表示第i层字符j的下一个字符的编号,cnt[i]用来标记以i号结点结束的单词的个数。
二、字典树的时间复杂度、空间复杂度:
时间复杂度:
假设所有字符串长度之和为n,构建字典树的时间复杂度为O(n)。
假设要查找的字符串长度为k,查找的时间复杂度为O(k)。
空间复杂度:
字典树每个结点都需要用一个数组来存储子结点的指针,即便实际只有两三个子结点,但依然需要一个完整大小的数组。所以,字典树比较耗内存,空间复杂度较高。 比如:按上述实现方式,假设有n个小写字母的字符串总长度≤105, 则空间复杂度为:105*26。