
搜索是基本的编程技术,在算法竞赛学习中是基础的基础。搜索使用的算法是BFS和DFS,BFS用队列,DFS用递归来具体实现。在BFS和DFS的基础上可以扩展出 A*算法、双向广搜算法、迭代加深搜索、IDA*等技术。
人们常说:“要利用计算机强大的计算能力。”如果答案在一大堆的数字里面,让计算机一个个去试,符合条件的不就是答案了吗?
没错最基本的算法思想”暴力法”就是这样。例如,银行卡密码是6位数字,共100万个,对于计算机来说,尝试100万次只需要一瞬间。不过计算机也不是无敌的。为了应对计算机强大的计算能力,可以对密码进行强化设计。例如网络账号密码,大部分网站都要求长度在8位以上,并且混合数字,字母,标点等。从40多个符号中选8个组成密码,数量有40x39x38x37x36x35x34x33>3万亿,即使使用计算机也不能很快算出来。
暴力法(Brute force,又称为蛮力法):把所有可能的情况都罗列出来,然后逐一检查,从中找到答案。这种方法简单,直接,不玩花样,利用了计算机强大的计算能力。
在算法竞赛中,枚举、深度优先搜索(DFS)、广度优先搜索(BFS)是最常使用的搜索方法。
虽然暴力法常常是低效的代名词,但是它仍然很有用,用好搜索算法, 基本上可以拿到提高组省一。原因如下:
1.很多问题只能用暴力法解决,例如猜密码。
2.对于小规模的问题,暴力法完全够用,而且避免了高级算法需要的复杂编码,在竞赛中可以加快解题速度。在竞赛中也可以用暴力法来构造测试数据,以验证高级算法的正确性。
3.把暴力法当作参照(benchmark)。既然暴力法是“最差”的,那么可以把它当作一个比较衡量另外的算法有多“好”。拿到题目后,如果没有其他思路,可以先试试暴力法,看是否能产生灵感。
不过在具体编程的时候通常需要对暴力法进行优化,以减少搜索空间,提高效率。例如利用剪枝技术跳过不符合要求的情况,从而减少复杂度。
虽然暴力搜索的思路简单,但是操作起来并不简单。一般有以下操作:
1.找到所有可能的数据,并且用数据结构表示和存储
2.剪枝。尽量多的排除不符合条件的数据,以减少搜索的空间
3.用某个算法快速检索这些数据。
其中第一步就可能很不容易。例如迷宫问题,如和列举从起点到终点的所有可能的路径?再如图论中的“最短路径问题”,在地图上任取两个点,它们之间所有可行的路径可能是一个天文数字,以至于根本无法一一列举出来。所以计算最短路径的Dijkstra算法使用贪心法,进行从局部扩散到全局的搜索,不能列举所有可能的路径。
暴力法的主要操作是搜索,搜索的主要技术是BFS和DFS。掌握搜索技术是学习算法的基础。在搜索时,具体问题会有相应的数据结构,例如队列,栈,图,树等。读者应该能熟练的在这些数据结构上进行搜索的操作。
本阶段主要学习BFS和DFS,以及基于它们的优化技术,并以一些经典的搜索问题为例讲解算法思想,例如排列组合,生成子集,八皇后,八数码,图遍历等。
一、深度优先搜索 (Depth-First-Search,DFS) 搜索过程实际上是根据初始条件和扩展规则构造一棵解答树并寻找符合目标状态的节点的过程。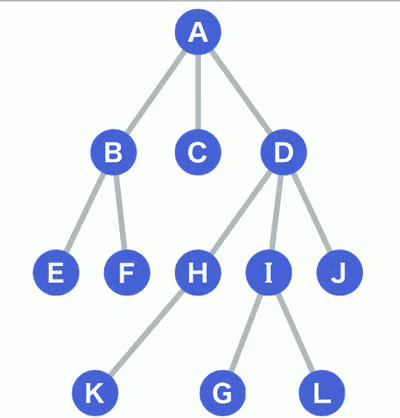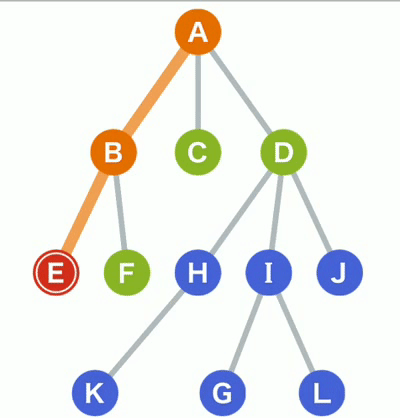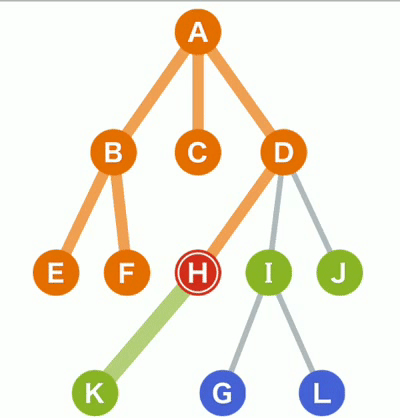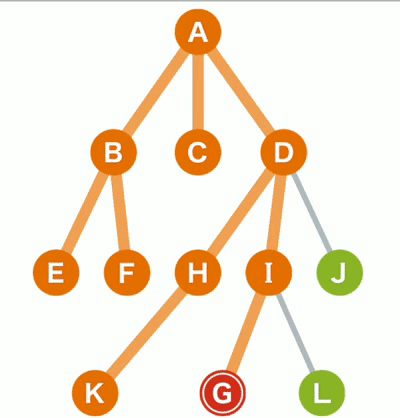 图例说明如下: 橙色 已经访问的树节点。蓝色 还没有访问过的树节点。绿色 在等待访问的树节点。
图例说明如下: 橙色 已经访问的树节点。蓝色 还没有访问过的树节点。绿色 在等待访问的树节点。
基本步骤演示
(1)对于上面的树而言,DFS方法首先从根节点A开始,其搜索节点顺序是A,B,E,F,C,D,H,K,I,G,L,J(假定左分枝和右分枝中优先选择左分枝)。
(2)从stack中访问栈顶的点;
(3)找出与此点邻接的且尚未遍历的点,进行标记,然后放入stack中,依次进行;
(4)如果此点没有尚未遍历的邻接点,则将此点从stack中弹出,再按照(3)依次进行;
(5)直到遍历完整个树,stack里的元素都将弹出,最后栈为空,DFS遍历完成。深度优先搜索 (Depth-First-Search)的思想 从一个顶点 V0 开始,沿着一条路一直走到底,如果发现不能到达目标解,那就返回到上一个节点,然后从另一条路开始走到底,这种尽量往深处走的概念即是深度优先的概念。
简单来说就是:一路走到头,不撞墙不回头。
回溯 是搜索算法中的一种控制策略。它的基本思想是:为了求得问题的解,先选择一种 可能情况向前探索,在探索过程中,一旦发现原来的选择是错误的,就退回一步重新选择, 继续向前搜索,如此反复进行,直至得到解或证明无解。
如迷宫问题:进入迷宫后,先随意选择一个前进方向,一步步向前试探前进,如果碰到死胡同,说明前进方向己无路可走,这时,首先看其它方向是否还有路可走,如果有路可走, 则沿该方向再向前试探;如果已无路可走,则返回一步,再看其它方向是否还有路可走;如果有路可走,则沿该方向再向前试探。按此原则不断搜索回溯再搜索,直到找到新的出路或从原路返回入口处无解为止。
DFS可用于解决2类问题:
1.从A出发是否存在到达B的路径(连通性问题);
2.从A出发到达B的路径数量(方案数)。
DFS框架模板如下:
void dfs(){ //搜索的参数设计根据题意确定
if(到达终点状态){
//根据题意添加逻辑
return;
}
if(越界或不合法状态) //边界
return;
if(特殊可剪枝状态) //优化剪枝
return;
for(扩展方式){ //尝试下一步的几个方向
... ...
if(扩展方式所达到状态合法){
修改操作;
标记;
dfs();//下一步
还原标记;//回溯,是否还原标记根据题意
}
}
}思考并尝试:
- 1、对于每个深搜问题,如何输出所有可行的解,即深搜的路径?
- 2、深搜能解决的问题规模最大是多大?
搜索实现组合:
排列:从n个不同元素中取出m (m≤n)个元素的所有排列的个数,叫做从n个不同元素中取出m个元素的排列数。
组合:从n个不同元素中取出m (m≤n)个元素的所有组合的个数,叫做从n个不同元素中取出m个元素的组合数。
详见:排列组合
二、广度优先搜索(Breadth First Search,BFS)
简称广搜,又称宽度优先搜索。它是从初始结点开始,应用产生式规则和控制策略生成第一层结点,同时检查目标结点是否在这些生成的结点中。若没有,再用产生式规则将所有第一层结点逐一拓展,得到第二层结点,并逐一检查第二层结点是否包含目标结点。若没有,再用产生式规则拓展第二层结点,得到第三层结点… …如此依次拓展,检查下去,直至发现目标结点为止。如果拓展完所有结点,都没有发现目标结点,则问题无解。
广度优先遍历类似于层次遍历。其特点是尽可能先对横向进行搜索, 从出发点开始, 按照该点的路径长度由短到长的顺序访问图中各顶点。
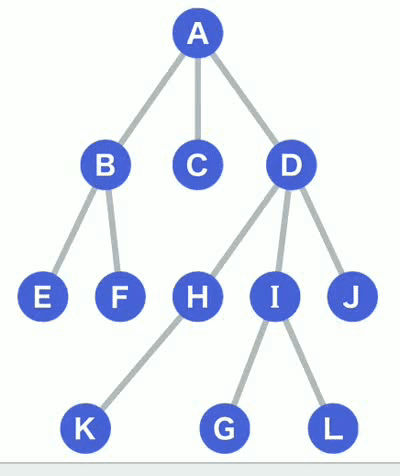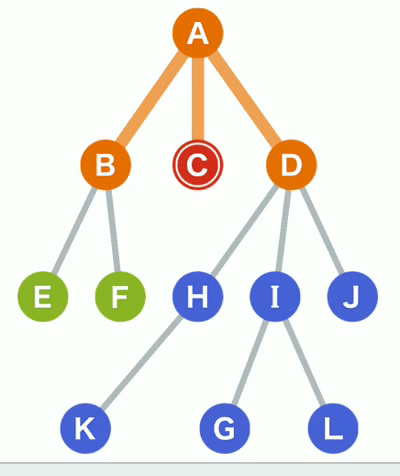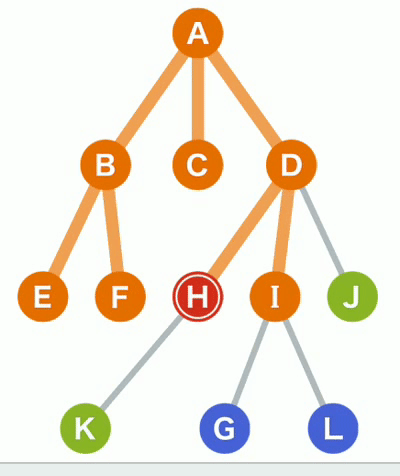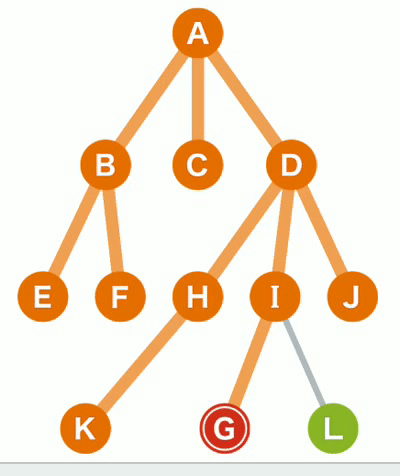
基本步骤演示
(1)给出一连通图,如图,初始化全是蓝色(未访问);
(2)搜索起点A(红色);
(3)已搜索A(橙色),即将搜索B,C,D(标绿);
(4)对B,C,D重复以上操作;
(5)直到终点L被染橙色,终止;
(6)可以找到从A点出发到任意一个点的最短路径.
BFS可用于解决2类问题:
- 从A出发是否存在到达B的路径(连通性问题);
- 从A出发到达B的最小步数。
BFS模板
void bfs(){
起点入队;
while(队列不为空){
获取对头元素;
if(到达终点状态) //得到问题的解
return;
for(扩展方式){ //拓展下一步的几个方向
... ...
if(扩展方式所达到的状态合法){
扩展点入队;
标记结点;
}
}
队首出队;
}
}三、DFS 和 BFS 的比较
我们假设一个节点衍生出来的相邻节点平均的个数是N个,那么当起点开始搜索的时候,队列有一个节点,当起点拿出来后,把它相邻的节点放进去,那么队列就有N个节点,当下一层的搜索中再加入元素到队列的时候,节点数达到了,那么,一旦N是一个比较大的数的时候,这个树的层次又比较深,那这个队列就得需要很大的内存空间了。
于是广度优先搜索的缺点出来了:在树的层次较深 子节点数较多的情况下,消耗内存十分严重。广度优先搜索适用于节点的子节点数量不多,并且树的层次不会太深的情况。
那么深度优先就可以克服这个缺点,因为每次搜的过程,每一层只需维护一个节点。但回过头想想,广度优先能够找到最短路径,那深度优先能否找到呢?深度优先的方法是一条路走到黑,那显然无法知道这条路是不是最短的,所以你还得继续走别的路去判断是否是最短路?
于是深度优先搜索的缺点也出来了:难以寻找最优解,仅仅只能寻找有解。其优点就是内存消耗小,克服了刚刚说的广度优先搜索的缺点。
| 实现方法 | 基本思想 | 解决问题 | 数据规模 | |
|---|---|---|---|---|
| DFS | 栈/递归 | 回溯法,一次访问一条路,更接近人的思维方式。 | 所有解问题如路径数量、方案数量,或连通性问题。 | 不能太大 |
| BFS | 队列 | 分治限界法,一次访问多条路,每一层需要存储大量信息。 | 最优解问题如最少步数,或连通性问题。 | 可以比较大 |
四、洪水填充算法
洪水填充是搜索算法的一个简单应用。
洪水填充(Flood fill)算法 从一个起始节点开始把附近与其连通的节点提取出或填充成不同颜色颜色,直到封闭区域内的所有节点都被处理过为止,是从一个区域中提取若干个连通的点与其他相邻区域区分开(或分别染成不同颜色)的经典算法。
因为其思路类似洪水从一个区域扩散到所有能到达的区域而得名。在GNU Go和扫雷中,Flood Fill算法被用来计算需要被清除的区域。
洪水填充算法接受三个参数:起始节点,目标节点特征和针对提取对象要执行的处理。目前有许多实现方式,基本上都显式的或隐式的使用了队列或者栈。
洪水填充算法实现最常见有四邻域填充法(不考虑对角线方向的节点),八邻域填充法(考虑对角线方向的节点),基于扫描线填充方法。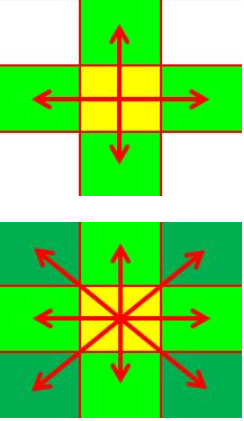 根据实现又可以分为递归与非递归。最简单的实现方法是采用深度优先搜索的递归方法,也可以采用广度优先搜索的迭代来实现。
根据实现又可以分为递归与非递归。最简单的实现方法是采用深度优先搜索的递归方法,也可以采用广度优先搜索的迭代来实现。
基于递归实现的泛洪填充算法有个致命的缺点,就是对于大的区域填充时可能导致栈溢出错误,基于扫描线的算法实现了一种非递归的洪水填充算法。
除提出连通区域外,还可以应用于计算从某一节点开始,到可能到达其他所有节点的距离。比如解决像走迷宫这类的问题。