
计算机只能识别两个数字:0 和 1。因此计算机中所有的信息:数值、字符、图形、视频、声音等都需要转换为0和1表示的代码,这个过程就是编码。
一、信息存储的单位
(1) 位 ( bit ,缩写为b):度量数据的最小单位,表示一位二进制信息。
(2) 字节 (byte,缩写为B): 一个字节由八位二进制数字组成(1byte=8bits)。字节 是信息存储的最小存储单位。
计算机存储器(包括内存与外存)通常也是以多少字节来表示它的容量。常用的单位有:
1千字节(KB)= 1024字节 (Bytes)
1兆字节(MB)= 1024千字节 (KB)
1吉字节(GB)= 1024兆字节 (MB)
1 TB = 1024 GB
1 PB = 1024 TB
(3) 机器字 (word):字是位的组合,并作为一个独立的信息单位处理。字又称为计算机字,它取决于机器的类型、字长以及使用者的要求。常用的固定字长有8位、16位、32 位、64位等。机器字长是指计算机进行一次整数运算所能处理的二进制数据的位数,机器字长反映了计算机的运算精度,即字长越长,数的表示范围也越大,精度也越高。机器的字长也会影响机器的运算速度。倘若CPU字长较短,又要运算位数较多的数据,那么需要经过两次或多次 的运算才能完成,这样势必影响整机的运行速度。
二、西文字符的编码表示-ASCII码 ASCII码 ( American Standard Code for Information Interchange ) 美国的标准信息交换代码,每个字符用7位的二进制数来表示,共有27=128种西文字符,包括大小字母、0…9、通用符(如+、=)、控制符(如回车、空格)。
ASCII码 ( American Standard Code for Information Interchange ) 美国的标准信息交换代码,每个字符用7位的二进制数来表示,共有27=128种西文字符,包括大小字母、0…9、通用符(如+、=)、控制符(如回车、空格)。
基本的ASCII码:存储时占据一个字节,最高位为0,范围0~127。
扩展的ASCII码:存储时占据一个字节,最高位为1,范围128~255。
外码:计算机与人进行交换的字形符号,如字符“A”的外码是“A”。
内码:计算机内部存储和使用的数字代码,如字符“A”的内码是65.
三、中文字符的编码表示-GB码
GB码即国标码,是汉字交换码,是计算机与其他系统或设备间交换汉字信息的标准编码。每个汉字使用2个字节进行编码,每个字节各取7位,可对27×27=16384个字符进行编码。
常见的GB2312-80 包含了6763个汉字。按使用频度分为一级汉字 3755个, 二级汉字 3008个. 一级汉字按拼音排序, 二级汉字按部首排序。另外还有标点符号, 图形, 数种西文字母等。
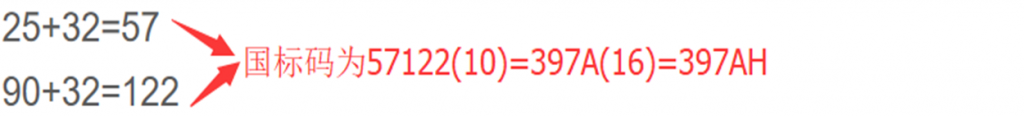

四、中文字符的编码表示-字形码
汉字字形码又称汉字字模,是表示汉字字形信息(结构、形状、比画等)的编码,以实现计算机对汉字的输出(显示、打印),字形码最常用的表示方式是点阵形式和矢量形式。 用点阵表示汉字字形时,字形码就是这个汉字字形的点阵代码根据显示或打印质量的要求,汉字字形编码有16×16,24×24,32×32,48×48等不同密度的点阵编码。点数越多,显示或打印的字体就越美观,但编码占用的存储空间也越大。如图所示,给出了一个16×16的汉字点阵字形和字形编码,该汉字字形编码需占用16×2=32个字节。如果是32×32的字形编码则占用32×4=128个字节。
用点阵表示汉字字形时,字形码就是这个汉字字形的点阵代码根据显示或打印质量的要求,汉字字形编码有16×16,24×24,32×32,48×48等不同密度的点阵编码。点数越多,显示或打印的字体就越美观,但编码占用的存储空间也越大。如图所示,给出了一个16×16的汉字点阵字形和字形编码,该汉字字形编码需占用16×2=32个字节。如果是32×32的字形编码则占用32×4=128个字节。
为了节省存储空间,普遍采用了字形数据压缩技术。所谓的矢量汉字是指用矢量方法将汉字点阵字模进行压缩后得到的汉字字形的数字化信息。
五、Unicode码
统一码(Unicode),也叫万国码、单一码,是计算机科学领域里的一项业界标准,包括字符集、编码方案等。Unicode是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。Unicode是国际组织制定的可以容纳世界上所有文字和符号的字符编码方案。UTF-8是目前互联网上使用最广泛的一种Unicode编码方式。
相关知识点:原码、反码、补码